
Deepgram
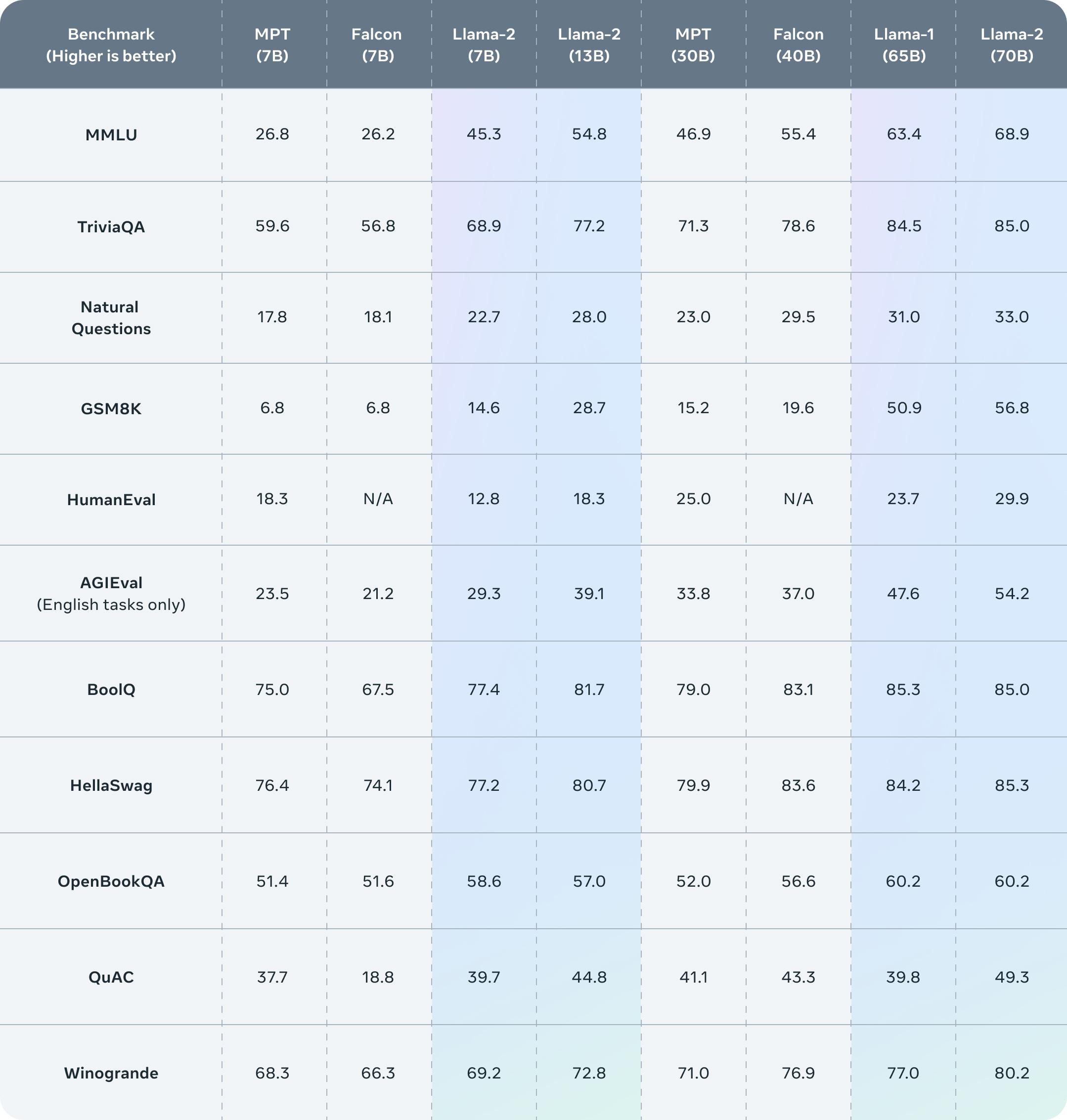
Variations Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned variations. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1 Llama 2 encompasses a series of. Fine-tune LLaMA 2 7-70B on Amazon SageMaker a complete guide from setup to QLoRA fine-tuning and deployment on Amazon Vocab_size int optional defaults to 32000 Vocabulary size. Llama 2 70B is substantially smaller than Falcon 180B Can it entirely fit into a single consumer GPU A high-end consumer GPU such as the NVIDIA. A new mix of publicly available online data A new mix of publicly available online data..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration. The base models are initialized from Llama 2 and then trained on 500 billion tokens of code data Meta fine-tuned those base models for two different flavors. I recommend using the huggingface-hub Python library Pip3 install huggingface-hub0171 Then you can download any individual model file to the current directory at high speed with a. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters This is the repository for the 7B pretrained model converted for the..

Mlops Blog Nimblebox Ai
Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration. Code Llama is a family of state-of-the-art open-access versions of Llama 2 specialized on code tasks and were excited to release integration in the Hugging Face ecosystem. This blog-post introduces the Direct Preference Optimization DPO method which is now available in the TRL library and shows how one can fine tune the recent Llama v2 7B-parameter. In this tutorial we will show you how anyone can build their own open-source ChatGPT without ever writing a single line of code Well use the LLaMA 2 base model fine tune. Llama 2 is being released with a very permissive community license and is available for commercial use The code pretrained models and fine-tuned models are all being released today..
LLaMA-2-7B-32K Model Description LLaMA-2-7B-32K is an open-source long context language model developed by Together fine-tuned from Metas original Llama-2 7B model. Today were releasing LLaMA-2-7B-32K a 32K context model built using Position Interpolation and Together AIs data recipe and system optimizations including FlashAttention. Llama-2-7B-32K-Instruct is an open-source long-context chat model finetuned from Llama-2-7B-32K over high-quality instruction and chat data. Last month we released Llama-2-7B-32K which extended the context length of Llama-2 for the first time from 4K to 32K giving developers the ability to use open-source AI for. In our blog post we released the Llama-2-7B-32K-Instruct model finetuned using Together API In this repo we share the complete recipe We encourage you to try out Together API and give us..



Comments